Designing for the Cliff: Calibrating Load to Reach maxmemory in a 1-Hour Run
This project has a hard contract: every run is exactly one hour. That constraint is what keeps results comparable across configurations and makes exported visualization consistent.
After I fixed shutdown reliability, the next issue wasn't infrastructure. It was methodology.
The discovery: the "happy path" trap
Reviewing telemetry from a standard run, I noticed that my default load generation (single ECS task) was not reliably pushing Redis into the state I actually care about.
Memory usage was climbing, but in many cases the run could finish without reaching maxmemory. That means the test is still useful as a smoke check, but it's not a strong performance validation: it mostly measures a cache that's not under pressure.
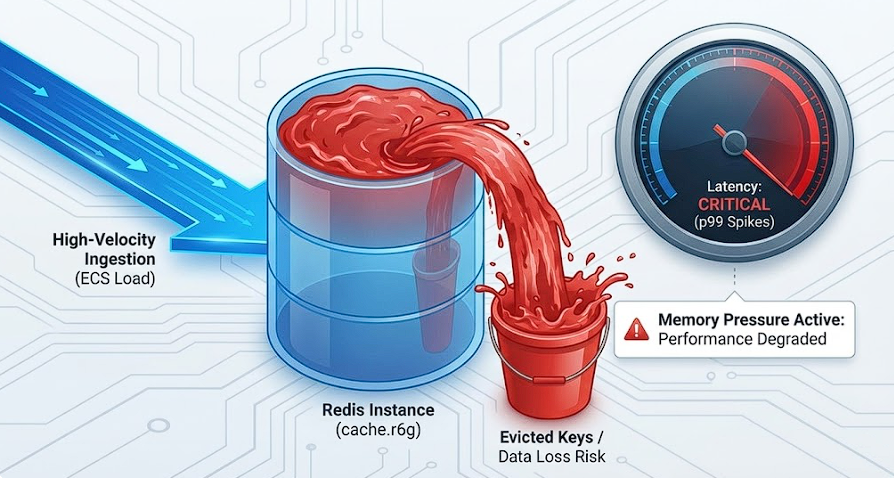
Why this matters for benchmark validity
Redis behaves differently at saturation. If the run never reaches sustained memory pressure, I'm not testing eviction behavior and the performance boundary conditions that show up when the cache is full.
So the benchmark needs more than "load ran for an hour". It needs a load shape that can reliably drive the system into the boundary state within the same one-hour contract.
Feature target: "maxmemory by minute X" (not solved yet)
The next feature target is explicit: reach maxmemory by a defined minute X inside the 60-minute window, leaving a consistent eviction-pressure window at the end.
Right now, I don't know what X can realistically be across instance types and configurations, because I haven't yet calibrated the fill velocity.
That becomes the next development step: determine what load is required to hit saturation inside the time box.
Current work: measuring fill velocity and discovering the required ECS task count
Instead of extending run time (which breaks comparability), I'm treating this as a calibration problem:
- increase parallelism (more ECS tasks) and/or payload density,
- observe time-to-maxmemory,
- and iterate until the run reliably reaches saturation within the hour.
The outcome of this step will be a baseline loader configuration: "for this cache size/config, the harness needs ~N ECS tasks (and a given payload profile) to reach memory pressure inside the one-hour contract."
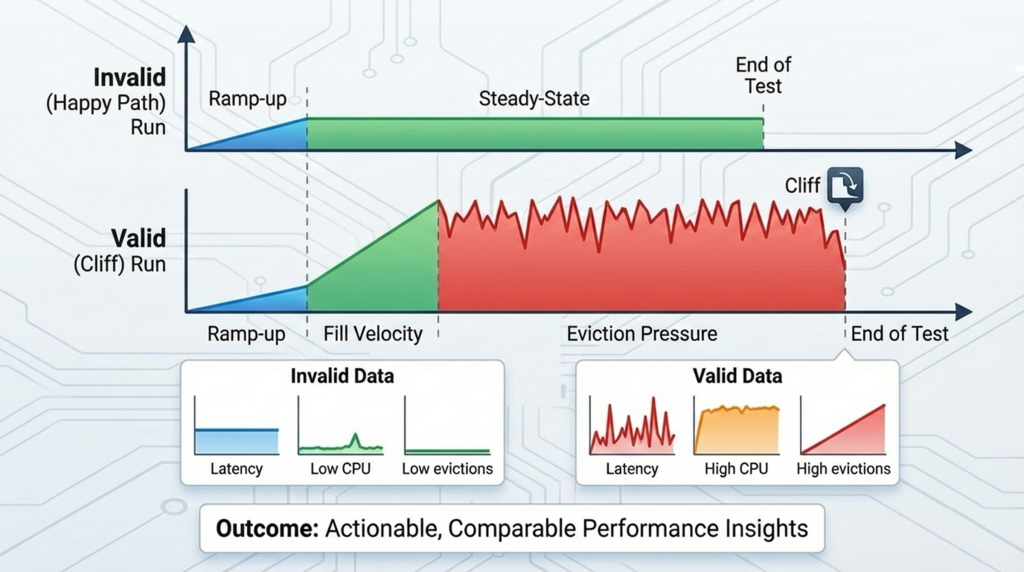
Once that's nailed down, the one-hour reports stop being "fresh-cache performance" and start being comparisons of how configurations behave at the cliff.